Locking – What is it, how and when to use it?
The answer is: Hopefully, you dont.

Quite an artist, right?
The nature of locks is to limit concurrency in software. Meaning, we are introducing waiting time, where the CPU is waiting and not being utilized.
Locking is a synchronization mechanism, used to control access to a resource. Usually, locking is used to allow only one thread to access the resource at any given moment. Different kinds of locks can be used in different scenarios, such as:
- Locks – allow a single access to the resource
- ReaderWriter locks – allows multiple readers or a single writer to access the resource
- Distributed locks – can be used across different instances of application.
The focus of this post is simple Lock.
Good usage of locks:
Historically, locks were used when an expensive operation needed to be done only once. An example is, creating a Database connection (this used to be considered expensive). Consider this code:
public class DbConnectionProvider
{
private readonly object _lock = new();
private DbConnection? _connection;
public DbConnection GetConnection()
{
if (_connection is not null)
{
return _connection;
}
lock (_lock)
{
if (_connection is not null)
{
return _connection;
}
_connection = ExpensiveConnectionCreationMethod();
return _connection;
}
}
}If there is not an existing instance of connection, the provider will acquire the lock, and then try to create the connection. If the connection exists, the existing instance will be returned. Of course, these days this is handled by Entity Framework so there is no reason to deal with this specific issue.
This is a good example because:
- The result is being cached
- The locking occurs only once per application instance
- The locking takes very little time, so the blocking of the threads is minimal
- The number of blocked threads is very small, if any
Incorrect usage of locks:
In some cases, there is a method that has to be executed by only one thread at any given moment. It can be tempting to wrap it in a lock and call it a day. It will work until it does not.
Consider the following code: There is an expensive method, and there are 10 threads created to invoke the method.
public class BadExample
{
public void Run()
{
var threads = Enumerable
.Range(0, 10)
.Select(_ => new Thread(ThreadStart))
.ToList();
threads.ForEach(x => x.Start());
threads.ForEach(x => x.Join());
}
private readonly object _lock = new();
void ThreadStart()
{
lock (_lock)
{
Console.WriteLine(ExpensiveMethod());
}
}
int ExpensiveMethod()
{
Thread.Sleep(1000);
return Random.Shared.Next();
}
}Why is this bad?
After all, it does exactly what we want it to.
The nature of locks is to limit concurrency in software. Meaning that we are introducing waiting time, where the threads are waiting and not being utilized.
We need to take a deeper look into the waiting and execution time for each thread:
- Thread 1: 0s waiting, 1s execution
- Thread 2: 1s waiting, 1s execution
- Thread 3: 2s waiting, 1s execution
- …
- Thread 10: 9s waiting, 1s execution
A total of 55 seconds of waiting time and 10 seconds of execution time. The effective CPU time is 10/55 = 18.18%.
The formula to calculate effective CPU time is Eff = 2/(N+1). Assuming each execution time is the same.
In some cases, we try to speed things up by throwing hardware at the problem. When using locks, any new hardware will simply wait for the lock to be acquired, even further reducing the effectiveness. For example, effectiveness for 100 threads would be 2/101 = 1.98%.
Increasing the efficiency
This image represents access to locked resources.
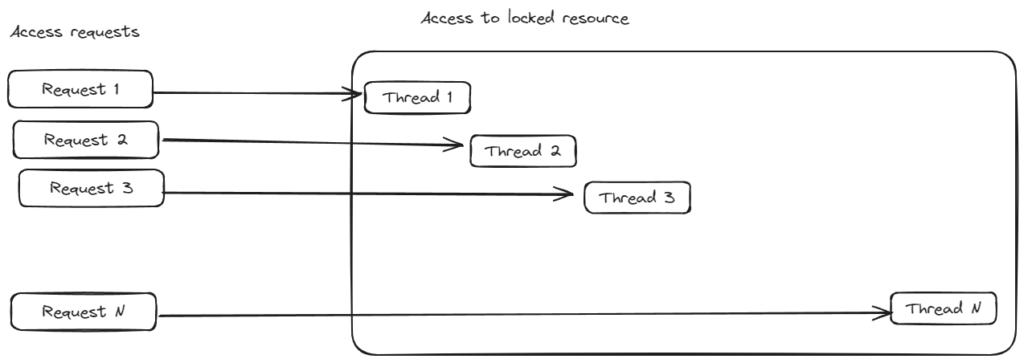
By taking a closer look, we can recognize that this is essentially a queue. It might not be recognizable in that image, so here is another one slightly rearranged:
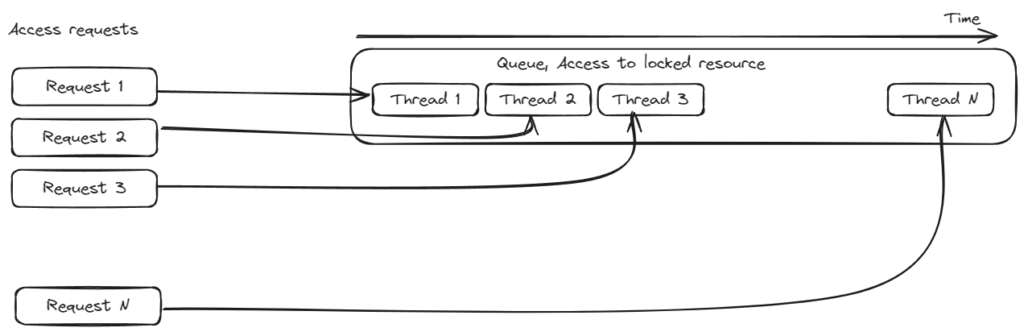
To increase the efficiency of the software, we can stop using locks as a queueing mechanism, and implement a real queue. In that case, instead of acquiring the lock, a new work item is created and put on the queue, and sometime later, we can check if the work item is processed.
The threads that were queueing the work are now free to be used for other work.
A code sample:
public record WorkItem(Guid Id);
public class QueueInsteadOfLocks
{
private readonly ConcurrentQueue<WorkItem> _queue = new();
private readonly ConcurrentDictionary<Guid, int> _results = new();
public void Run(CancellationToken cancellationToken)
{
var processingTask = new Task(() => ProcessWorkItems(cancellationToken));
processingTask.Start(TaskScheduler.Default);
}
public void Enqueue(WorkItem workItem)
{
_queue.Enqueue(workItem);
}
async Task ProcessWorkItems(CancellationToken cancellationToken)
{
while (!cancellationToken.IsCancellationRequested)
{
if (!_queue.TryDequeue(out var workItem))
{
await Task.Delay(TimeSpan.FromMicroseconds(100), cancellationToken);
continue;
}
var result = ExpensiveMethod();
_results.TryAdd(workItem.Id, result);
}
}
int ExpensiveMethod()
{
Thread.Sleep(1000);
return Random.Shared.Next();
}
public bool TryGetResult(Guid workItemId, out int result)
=> _results.TryGetValue(workItemId, out result);
}A sample usage, where 10 work items are added to the queue:
var cts = new CancellationTokenSource();
var queue = new QueueInsteadOfLocks();
queue.Run(cts.Token);
var workItemIds = Enumerable.Range(0, 10)
.Select(_ =>
{
var workItem = new WorkItem(Guid.NewGuid());
queue.Enqueue(workItem);
return workItem.Id;
})
.ToList();
// Some time later, check for results
await Task.Delay(5000);
foreach (var workItemId in workItemIds)
{
if (queue.TryGetResult(workItemId, out var value))
{
Console.WriteLine($"{DateTime.Now.ToLongTimeString()} Work item {workItemId} has result: {value}");
}
}
cts.Cancel();And the result:
6:48:23 PM Work item 7077eaa1-9f8d-40b8-bc47-8661c5d48642 has result: 301646615
6:48:23 PM Work item 4552f84a-5ce6-41dd-ae77-f70f309c7a40 has result: 1320433100
6:48:23 PM Work item 22d36ce0-f1ab-49ea-be8e-467cf96a4180 has result: 226035070
6:48:23 PM Work item 07d43ad0-0fcc-4483-92d5-e9606f55959e has result: 2056302106
6:48:23 PM Work item d0f092c4-8a0c-4f3a-9389-0d12e024457e has result: 1692952982Speeding up the processing
Depending on the workload, sometimes it is possible to speed up the processing of the queued work items. Some approaches are:
- Try to partition the work items – If not all work items are related to the same resource (the one we acquired the lock for), partitioning the work items by a meaningful key will create multiple queues, but processing can be parallelized.
- Try skipping some of the work items – In some cases, work items are queued, but only the latest version needs to be processed. In that case, drop all the work items except the last one and process only that one.
Notes
The code samples are just that, samples. They are not suitable for production use. Same principles can apply, but the results need to be stored in a durable storage such as database, and queue needs to be durable, such as Rabbit MQ.
Distributed locks
They work exactly as the non-distributed ones. However, make sure to release the lock after usage, so it can be reacquired
Do not try to roll out your own distributed locks, and instead use existing libraries. Here is one such library: GitHub – madelson/DistributedLock: A .NET library for distributed synchronization