
The solution so far managed to queue 837,000 messages, and 449,274 of them were processed. Both, the producer and the consumers did not manage to handle the 1 million we need.
The previous blog post ended with a list of potential bottlenecks that we can explore:
- SQL Server – Optimize usage of SQL server
- RabbitMQ – Fine-tune the message broker
- Multithreading – Try to reduce context switching
Optimizing SQL Server
In part 1 of the series, a script was added that inserts millions of records in a couple of seconds. The difference is, that the script works by doing bulk inserts. SQL Server can handle the load when used correctly.
When handling the messages coming from RabbitMQ, the rows are inserted one by one. To understand if the database can handle 1 million inserts per minute with the algorithm used so far, I made a SQL script that loops 10,000 times and inserts the data.
declare @start DATETIME2(7) = (SELECT GETDATE());
declare @count int = 1;
declare @rowsToInsert int = 10000;
declare @max int = (select MAX(Id) from Notifications)
while @count <= @rowsToInsert
begin
insert into Notifications values (@count + @max, '{}', GETDATE())
set @count = @count + 1;
end
declare @end DATETIME2(7) = (SELECT GETDATE());
SELECT DATEDIFF(millisecond, @start, @end) AS elapsed_ms;This script took 27 seconds to execute. To insert 1 million records, it would take 27 * 100 seconds = 45 minutes. This is a blocker.
Back to the requirements
Why do we need to store the notification logs in the database anyway? In this case, it was used only to look up if the notification has been processed so far, due to potential duplication of messages.
private async Task Send(BasicDeliverEventArgs @event)
{
var notification = JsonSerializer.Deserialize<Notification>(Encoding.UTF8.GetString(@event.Body.Span))
?? throw new Exception();
await using var scope = _serviceProvider.CreateAsyncScope();
await using var dbContext = scope.ServiceProvider.GetRequiredService<NotificationContext>();
var isAlreadyHandled = await dbContext.NotificationLogs.AnyAsync(x => x.Id == notification.Id);
if (isAlreadyHandled)
{
return;
}
await _emailService.Send(notification.Payload);
dbContext.NotificationLogs.Add(new NotificationLog
{
Id = notification.Id,
SentDate = DateTime.UtcNow
});
await dbContext.SaveChangesAsync();
MessagesHandled++;
}If we can replace the calls to the database with something faster, the program would still be correct, but the bottleneck will not be there.
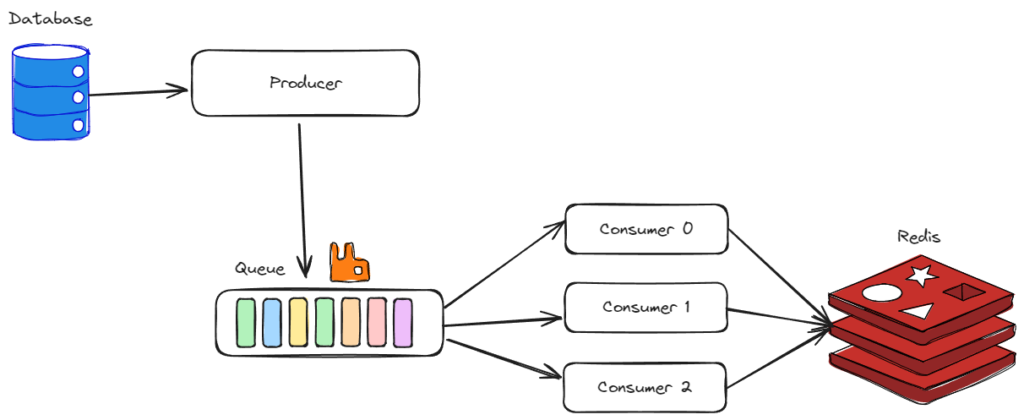
Redis
A good solution for the problem at hand is to use Redis. It is blazing fast and can be used to store notifications that have been processed for some time.
Using Redis gives us another hidden benefit: there is no need to create a new ServiceScope and resolve the NotificationContext. The improvement is huge. Previously, handling one message would take 26ms when tested locally. Now it takes 12 ms (10 ms are still used for the notification itself). A reduction of 53%!
The architecture with Redis:
The code of the consumer:
private async Task Send(BasicDeliverEventArgs @event)
{
var notification = _serializer.Deserialize<Notification>(@event.Body)
?? throw new Exception();
var isAlreadyHandled = await _notificationLogCache.IsHandledAsync(notification.Id);
if (isAlreadyHandled)
{
return;
}
await _emailService.Send(notification.Payload);
await _notificationLogCache.AddAsync(new NotificationLog
{
Id = notification.Id,
SentDate = DateTime.UtcNow
});
MessagesHandled++;
}On the development machine, this change was enough to increase the number of handled messages from 44k to 206k messages per minute. At this moment, I was happy to try this on the horizontally scaled cluster, only to hit another bottleneck.
Optimizing the Producer
The producer was unchanged and still produced around 800-900k messages. To get more, we can either horizontally scale it, or try to improve the algorithm.
The algorithm at this moment was reading N messages, publishing them to the queue, and then removing them from the database.
private async Task<int> PublishNextBatch(IModel channel, int batchSize)
{
await using var scope = serviceProvider.CreateAsyncScope();
await using var dbContext = scope.ServiceProvider.GetRequiredService<NotificationContext>();
var notifications = await dbContext.Notifications
.Where(x => x.SendDate < DateTime.UtcNow)
.Take(batchSize)
.ToListAsync();
if (notifications.Count == 0)
{
return 0;
}
dbContext.RemoveRange(notifications);
notifications
.ForEach(x =>
{
var messageBody = Encoding.UTF8.GetBytes(JsonSerializer.Serialize(x));
var props = channel.CreateBasicProperties();
props.DeliveryMode = 2; // Persistent
channel.BasicPublish(string.Empty, "notifications", true, props, messageBody);
});
await dbContext.SaveChangesAsync();
return notifications.Count;
}How can this be improved? The slowest part in this code is – SQL Server. Calling RemoveRange method will create multiple queries, and I wanted to improve it.
Step 1:
When loading notifications, use AsNoTracking() and order them by ID:
var notifications = await _dbContext.Notifications
.AsNoTracking()
.Where(x => x.SendDate < now)
.OrderBy(x => x.Id)
.Take(_batchSize)
.ToListAsync();Step 2:
When deleting the notifications, instead of using RemoveRange, use ExecuteDeleteAsync() instead, which executes directly on the database. No transaction is needed:
await _dbContext.Notifications
.Where(x => x.Id <= notifications[notifications.Count - 1].Id)
.Where(x => x.SendDate < now)
.ExecuteDeleteAsync();With these changes, the producer was able to publish a whooping 2,910,000 messages per minute.
However, it did not work as intended. The producer did create that many messages and called publish, but they were not published to the queue. They were stuck in RabbitMQ.Client internal cache, and waiting to be published.
To prevent this from happening, after each batch of messages is published, we have to wait for RabbitMQ to acknowledge them. It can be done with a one-line call:
channel.WaitForConfirmsOrDie(TimeSpan.FromSeconds(5));However, with this change, the producer produced only 920k messages, just a bit short of 1 million.
The good side is that the consumer side had no trouble keeping up with the load with 3 instances running.
Handling RabbitMQ Bottleneck
At this moment, I was not sure how to improve the performance of RabbitMQ. Perhaps a cluster of instances would increase the performance? Or using multiple queues?
Instead, I decided on a simple solution: Each message that is published to RabbitMQ will contain 10 notifications, instead of a single notification.
The producer now creates chunks when publishing the notifications:
var batch = channel.CreateBasicPublishBatch();
notifications
.Chunk(10)
.ToList()
.ForEach(chunk =>
{
var messageBody = _serializer.Serialize(chunk);
batch.Add(string.Empty, "notifications", true, props, messageBody);
});
batch.Publish();
channel.WaitForConfirmsOrDie(TimeSpan.FromSeconds(5));The consumer iterates through the chunk and handles each one separately:
private async Task Send(BasicDeliverEventArgs @event)
{
var notifications = _serializer.Deserialize<Notification[]>(@event.Body)
?? throw new Exception();
foreach (var notification in notifications)
{
var isAlreadyHandled = await _notificationLogCache.IsHandledAsync(notification.Id);
if (isAlreadyHandled)
{
continue;
}
await _emailService.Send(notification.Payload);
await _notificationLogCache.AddAsync(new NotificationLog
{
Id = notification.Id,
SentDate = DateTime.UtcNow
});
MessagesHandled++;
}
}Results
| No. of Producers | Messages produced | No of notifications | No. of Consumers | Notifications handled | No. of Servers | Consumer & Producer CPU usage | Database & Rabbit CPU % |
|---|---|---|---|---|---|---|---|
| 1 | 238,000 | 2,380,000 | 3×96 | 1,321,975 | 2 | 8/16 cores | 6/16 cores |
Judging the solution
- Simplicity – Relatively simple to understand, although 3 external components are now used, 3/5
- Scalability – 1.3 million per minute. It was possible to spin up new consumers to increase the throughput – 5/5.
- Infrastructural complexity – We still allow only one producer. However, the consumer can be added to any existing service, making it simple to integrate – 4/5
Bonus:
The initial goal was to serve more than 1 million requests per minute. That goal has been achieved. It is possible to go further, however that does not make sense, if there is no need for it.
For comparison, Azure Service bus allows up to 2,000 messages per second, or 120,000 messages per minute. The solution here is 10x that number.
In this series, the actual notification handling is sending an email which takes 10 ms. However, it was simply waiting, and that does not use any CPU. If it was a more CPU-intensive process, the number of handled notifications would be reduced. This solution would still be able to handle that many notifications – although many more servers would be needed to handle that load.
Using MessagePack to serialize messages
To send the message over the network, it has to be serialized to byte[]. Initially, that was done by serializing the data to JSON and then getting the raw bytes of the string. However, a better solution is to use a binary serializer, which will produce much smaller messages, and do it faster. One such solution is MessagePack.
Further scaling
To continue the scaling process, we have to go back to the basics and try to understand what the bottleneck could be:
- Algorithm – the code is not stateless and therefore not scalable
- External dependencies – the way the external dependencies are (mis)used can be a limiting factor.
My focus would be on the external dependencies. For example, RabbitMQ could not receive more than 1 million messages on a single queue. Would having multiple instances of RabbitMQ help increase the throughput? Perhaps Kafka can be used instead? Do we need to create different queues, effectively partitioning the data?
At some point, we can hit the limit on Redis as well. Can we use multiple instances of Redis, or use some other tool that allows multi-master scaling?
On the algorithm side, the producer will hit the limit soon. Is it possible to have multiple producers that do not step on each other toes?
Links
- Scaling a notification service, Part 3 – Horizontal scaling – Engineering With Filip
- Scaling a notification service, Part 2 – Multithreading – Engineering With Filip
- Scaling a notification service – Part 1 – Engineering With Filip
- PavlovicDzFilip/scalable-notification-service at v5 (github.com)
- MessagePack-CSharp/MessagePack-CSharp: Extremely Fast MessagePack Serializer for C#(.NET, .NET Core, Unity, Xamarin). / msgpack.org[C#] (github.com)
- Truly thrifty cloud hosting – Hetzner Online GmbH