
In the previous part, we created a simple, single-threaded solution that does not scale.
The CPU utilization was around 1%. We can improve this by creating multiple threads until the CPU hits the 100% mark.
Note that does not mean we can spawn 100 threads to get the best performance. The cost of context switching will become too high at some point, and we will get diminishing, if not negative returns.
Multithreading
Multithreading is running multiple threads concurrently. Compared to single threaded programming, this technique allows concurrent data processing.
When using multithreading, it is important to have a mechanism to split the workload, so that two or more threads to not try to process the same data. Processing the same data is redundant, and in many cases incorrect. In the case at hand, multiple notifications would be sent and performance would be impacted, which is not ideal.
Partitioning
Splitting the workload into smaller sets is called partitioning. A simple way to achieve this is to use the round-robin method, which splits the workload into smaller, evenly-sized data sets.
For example, we have 3 threads, and 5 items to process:
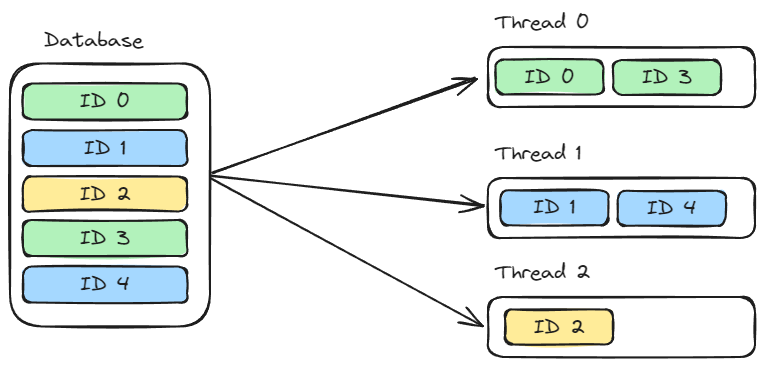
To correctly partition the data, we need:
- The number of total partitions (in our case, threads)
- What is the partition key for each consumer (in our case, thread)
- A function that determines to which partition an item belongs to.
Handling single partition data
The code introduces a new class SinglePartitionNotificationSender , which handles notifications in a single partition. It reads the first notification belonging to the partition, and handles it, the same way as previous implementation did.
The partitioning is done by applying mathematical Modulo function :
var notification = await dbContext.Notifications
.FirstOrDefaultAsync(x =>
x.Id % numberOfPartitions == partitionKey &&
x.SendDate < DateTime.UtcNow);It is important to recognize one detail: Id of the notification is used to to partition the data. In case Ids are not evenly distributed, some partitions will end up with larger data sets, and some with smaller data sets.
This will be properly handled in one of the later implementations.
The query this code will produce is also optimized: SendDate already has an index, and Id is part of the index as it is the primary key. SQL Server can use that index to do INDEX SCAN (although, not a full one, only until first row is matched) to very quickly return the data.
The whole class:
public class SinglePartitionNotificationSender(
IServiceProvider serviceProvider,
IEmailService emailService,
int partitionKey,
int numberOfPartitions)
{
public async Task<int> Send(CancellationToken cancellationToken)
{
var totalNotificationsSent = -1;
bool hasMoreNotifications;
do
{
hasMoreNotifications = await TrySendNext();
totalNotificationsSent++;
} while (hasMoreNotifications && !cancellationToken.IsCancellationRequested);
return totalNotificationsSent;
}
private async Task<bool> TrySendNext()
{
await using var scope = serviceProvider.CreateAsyncScope();
await using var dbContext = scope.ServiceProvider.GetRequiredService<NotificationContext>();
var notification = await dbContext.Notifications
.FirstOrDefaultAsync(x =>
x.Id % numberOfPartitions == partitionKey &&
x.SendDate < DateTime.UtcNow);
if (notification is null)
{
return false;
}
await emailService.Send(notification.Payload);
dbContext.Notifications.Remove(notification);
dbContext.NotificationLogs.Add(new NotificationLog
{
Id = notification.Id,
SentDate = DateTime.UtcNow
});
await dbContext.SaveChangesAsync();
return true;
}
}Another class, MultithreadedPartitionedNotificationSender is used to create multiple SinglePartitionNotificationSenders. IConfiguration is used to read the number of partitions, and the Send method simply invokes Send on all partition senders.
The tasks created in the Send method are queued on the ThreadPool, and will be executed whenever a thread is free.
public class MultithreadedPartitionedNotificationSender
{
private readonly SinglePartitionNotificationSender[] _senders;
public MultithreadedPartitionedNotificationSender(
IServiceProvider serviceProvider,
IEmailService emailService,
IConfiguration configuration)
{
var numberOfPartitions = configuration.GetValue<int>("NumberOfPartitions");
_senders = Enumerable.Range(0, numberOfPartitions)
.Select(x => new SinglePartitionNotificationSender(serviceProvider, emailService, x, numberOfPartitions))
.ToArray();
}
public async Task<int> Send(CancellationToken cancellationToken)
{
var tasks = _senders.Select(x => x.Send(cancellationToken)).ToArray();
await Task.WhenAll(tasks);
return tasks.Sum(x => x.Result);
}
}To get the best value for number of threads, we have to run this multiple times. The CPU I use for this test is Intel i7 7700HQ with 4 cores and 8 threads. This information is important when trying to determine what is the number of threads to start. On different hardware, the results will vary.
The test results are:
| No. of Threads | No. of Notifications sent |
|---|---|
| 4 | 7299 |
| 8 | 13534 |
| 16 | 18509 |
| 32 | 25317 |
| 64 | 28330 |
The diminishing returns are visible. Increasing the number of threads beyond this point will not bring any meaningful increase, and can decrease the performance.
Handling failure
If one of the threads fail and stops running, the data in that partition will not be processed. It is not possible to introduce multiple threads to process data in the same partition – that would bring the same problem as described at the beginning of this post.
Judging the solution
- Simplicity – Still relatively simple, 5/5
- Scalability – 28k per minute. Far from what we are trying to achieve and it is still not possible to horizontally scale this solution. 1/5.
- Infrastructural complexity – This approach has exactly the same issues as the one described in the previous blog post Scaling a notification service – Part 1 – Engineering With Filip, so the complexity is still 4/5.
Understanding the bottleneck
By introducing multithreading, we utilize the CPU fully. To scale more than this, we need horizontal scaling and multiple servers to handle the load.
Stay tuned for the next post: Introducing horizontal scaling