
When writing a simple query, we often check if there’s an index for all the fields we filter on. The query performs well in both local and production environments, and we don’t think twice about it. However, certain conditions can cause system failure. Let’s explore this further.
The Setup
For this demonstration, I’m using code similar to the one in the Scaling a notification service Series.
We have a table created as follows:
CREATE TABLE [dbo].[Notifications](
[Id] [bigint] NOT NULL,
[Payload] [nvarchar](1000) NOT NULL,
[SendDate] [datetime2](7) NOT NULL,
PRIMARY KEY CLUSTERED([Id] ASC))
CREATE NONCLUSTERED INDEX [IX_SendDate] ON [dbo].[Notifications]([SendDate] ASC)We’re using Entity Framework Core to get records where SendDate is between two dates. Note the index IX_SendDate on this column.
Task<Notification[]> GetNotifications(DateTime startDate, DateTime endDate)
{
return dbContext.Notifications
.Where(x => x.SendDate > startDate && x.SendDate <= endDate)
.ToArrayAsync();
}The SQL query produced by EF Core is as follows:
exec sp_executesql N'SELECT [n].[Id], [n].[Payload], [n].[SendDate] FROM [Notifications] AS [n]
WHERE [n].[SendDate] > @__startDate_0 AND [n].[SendDate] <= @__endDate_1',N'@__startDate_0 datetime2(7),@__endDate_1 datetime2(7)',@__startDate_0='2024-03-11 17:22:05',@__endDate_1='2024-03-12 17:22:05'In my dataset, only a few records will match the query, regardless of the dataset size.
The Issue
The IX_SendDate index is created on the SendDate column and includes the Id column. The EF Core query selects three columns: Id, Payload, and SendDate. Our index lacks the Payload column, so SQL Server must perform a Key Lookup and read the data from the disk, which is slow.
Consider these scenarios:
Scenario 1: Local Environment with 1,000 Records
The database has 1,000 records. To execute the query, the database doesn’t use the IX_SendDate index. Instead, it finds it cheaper to:
- Read each row from the disk
- Filter the data in memory
- Select rows that match the query predicate.
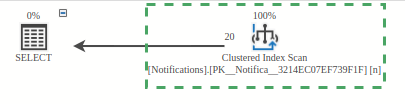
The problem is the first point – reading each row from the disk. In my case, to get around 20 records, the database had to read 1000 records. This is hardly optimal, although it performs ok for now.
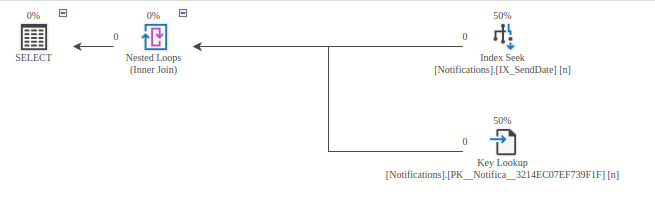
Scenario 2: Production Environment with 10,000 Records
The database has 10,000 records. This time, the database used the IX_SendDate index to get the ids of notifications. Then, a Key Lookup is performed to get the whole row. In this case, the database reads the least required data, offering the best performance.
Ok, what exactly is the problem?
In both scenarios, EF Core generated the same query with same arguments. The only difference is the number of records in the database.
The problem is that the query execution plan changes based on the dataset size, and we have no way of knowing when it uses one plan or the other. The database selects one execution plan or the other based on statistics.
To make matters worse, while we’re developing, we usually have a small dataset, and the performance problem is unlikely to show itself.
Real World occurrence
A table in the system I am working on has hundreds of millions of records. During normal operations, SQL Server decided to start using the first query instead of the second, effectively performing table scan every time data was requested.
Why did SQL Server start using a different query execution plan? I’m not sure. There were no changes during that time. Scaling up the Azure SQL Server instance reset some internal cache, and the correct query execution plan was used once again.
To demonstrate the difference in the query execution, the same query was run with and without the index on different dataset sizes:
| No. of Records | Query No 1, CPU time (ms) | Query No 1, logical reads | Query No 2, CPU time (ms) | Query No 2, logical reads |
|---|---|---|---|---|
| 1,000 | 0 | 8 | 0 | 9 |
| 10,000 | 2 | 44 | 0 | 9 |
| 100,000 | 56 | 437 | 0 | 9 |
| 1,000,000 | 96 | 4135 | 0 | 9 |
| 10,000,000 | 948 | 41043 | 0 | 9 |
Execution time of the first query is increasing linearly, while it stays the same for the second one. Note on query 2: depending on where the data is in the index, number of logical reads might wary a bit, but will be in the same ballpark.
In my case, these queries started taking a few seconds each – when you are handling thousands of requests per second, this will bring your system down.
The Solution
The root of the problem is that we need data which is not in the index. Such an index is called a Non-Covering index.
Preferred solution: Split the query into 2 queries
Query 1: Read only the primary key where criteria matches. As noted above, the primary key is always included in the index. In this case, we read only the Id column by filtering on SendDate. The existing IX_SendDate is a covering index for the query, and will perform consistently well.
Query 2: Read the records by using the primary key values returned by query 1. This is a Key Lookup, and while it involves going to the disk, we are reading only the records we want to read. There is no filtering on those values.
Code sample:
async Task<Notification[]> GetNotifications(DateTime startDate, DateTime endDate)
{
// IX_SendDate is covering index for this query, we are getting only the Id, not the whole record.
var notificationIds = await dbContext.Notifications
.Where(x => x.SendDate > startDate && x.SendDate <= endDate)
.Select(x => x.Id)
.ToArrayAsync();
// Get records by Id. WhereIn is a custom extension.
return await dbContext.Notifications
.WhereIn(x => x.Id, notificationIds)
.ToArrayAsync();
}For 10 million records, the queries produced take 0 milliseconds and perform only 24 logical reads. And most importantly, there is no risk of changing the execution plan in the middle of the night.
You might notice that the 2 queries we have now are exactly the same as what SQL Server does in the scenario #2 described above. That is correct. At the cost of a little IO, we ensure a covering index is always used, and therefore the risk of performing Table Scan is eliminated.
Other solutions:
Solution 1: Make the index a Covering Index
If all required columns are part of the index or included in the index, the query would be served from the index. SQL Server does not need to read data from the disk. This is useful when we need only bits of information. But when we need the whole row, as is the case when working with aggregate roots, it is not a good solution. The size of the index would grow too much.
And if we have multiple indexes, and follow the same approach
Solution 2: Use raw SQL and FORCESEEK to query the database
It is possible to change the original query and add WITH (FORCESEEK) so the database will be forced to use the index + Key Lookup:
SELECT [n].[Id], [n].[Payload], [n].[SendDate]
FROM [Notifications] AS [n] WITH(FORCESEEK)
WHERE [n].[SendDate] > @__startDate_0 AND [n].[SendDate] <= @__endDate_1This solution will perform better than the preferred solution. There is no back and forth to the server with list of Ids. SQL Server returns only needed rows.
Even if that is the case, I am not a fan of the approach. Writing queries by hand is tedious, prone to errors and the queries have to be changed when the table structure changes. This is exactly the reason why ORMs are invented in the first place.
Links:
- GitHub repository with code samples
- WhereIn extension
- Notification class – taken from Scaling a notification service series
FAQ
What is a non-covering index?
- A non-covering index is an index that does not include all the columns that are needed for a particular query. This means that the database has to perform an additional step, known as a key lookup, to retrieve the necessary data from the disk, which can be slow.
What is a covering index? - A covering index is an index that includes all the columns that are needed for a particular query. This means that the database can retrieve all the necessary data directly from the index without having to perform a key lookup, which can significantly improve query performance.
Why does the query execution plan change based on the dataset size? - The database’s query optimizer chooses the execution plan that it estimates will be the most efficient based on the current statistics about the data. These statistics include information about the distribution and density of the data, the number of rows in the table, and the number of pages that the data occupies on disk. As the data changes, these statistics change, and the query optimizer might choose a different execution plan.
Fast Data Seeding
declare @numberOfRows int = 10000000;
declare @count int = (select COUNT(0) from Notifications)
if @count = 0
begin
insert into Notifications values (1, '{}', '2024-03-11 16:30:00')
end
while @count < @numberOfRows
begin
declare @max int = (select MAX(Id) from Notifications)
insert into Notifications
select Id + @max, Payload, DATEADD(MINUTE, (Id + @max), SendDate) FROM Notifications
set @count = (select COUNT(0) from Notifications)
end
delete from Notifications
where Id > @numberOfRows