I’ve received a question from a reader (thanks Ishthiyaque Ahmed | LinkedIn!) about EFCore AsNoTracking performance. The question contains an image of a BenchmarkDotNet table result:
| Method | NumBlogs | Mean | Ratio |
|------------------------|----------|-----------|--------------|
| LoadEntities | 1000 | 3.587 ms | baseline |
| LoadEntitiesNoTracking | 1000 | 1.534 ms | 2.34x faster |
| | | | |
| LoadEntities | 5000 | 21.981 ms | baseline |
| LoadEntitiesNoTracking | 5000 | 6.185 ms | 3.56x faster |
| | | | |
| LoadEntities | 10000 | 45.893 ms | baseline |
| LoadEntitiesNoTracking | 10000 | 12.315 ms | 3.73x faster |Question text:
According to this, is that a practice in general we always query as no tracking? During our usual code practice is there any place where we query with tracking and without tracking?
The code being tested shows loading from database N number of blogs, with and without Change Tracking.
Number of iterations tested are 1000, 5000, and 10000, and the results show AsNoTracking wins in performance every single time, by being 2.34, 3.56, and 3.73 times faster.
The answer
There are generally a few approaches I’ve seen, used at large:
- Use the default change tracker behavior
- Use Identity Resolution change tracker behavior
- Use CQRS to separate read and write queries, and then have different behavior based on your needs
The question is, which one is the best?
The obvious answer: The one that fits your specific use case.
Let’s consider the following very different apps.
Case 1: A web application
Workloads for a typical web application include:
- Reading a single entity
- Reading a list of same-type entities (or a part of them). List sizes might be 10, 20, 50, or 100.
- Reading and updating/deleting a few entities.
In this case, all three approaches would work. The performance penalty that we are trying not to pay is not worth paying attention. Consider the usual Web Request flow:
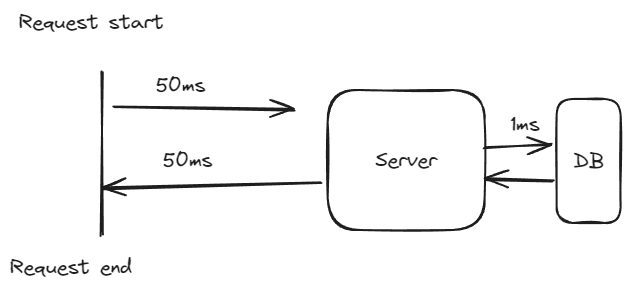
What we are trying to do here is to optimize one part of the whole request flow (parsing of database query results), which takes the least time! If I were to optimize something, I’d look elsewhere:
- Usually, the longest time is the network trip from the user to our server
- Next, it might be worth looking into the slow queries and indexing. Many queries are unoptimized and take hundreds of milliseconds
In the image above, the total request time might take 102ms or more (not counting database query execution time + request processing time), and we are looking to optimize perhaps 2ms? I can’t justify spending my time on such low impact work.
Case 2: An app that processes large amounts of data
In some cases, you might need to load a bunch of data from the database and process it. In most of these cases, the data is needed only for reading. These cases are usually some background processing or report generation. Using AsNoTracking() makes perfect sense here.
How do I use AsNoTracking()?
There are a few systematic ways to set up your code base, and they are variants of CQRS:
Separate read and write repositories
In the constructor of read-only repository, apply the AsNoTracking() and use the resulting IQueryable:
public class UsersRepository
{
private readonly IQueryable<User> _users;
public UsersRepository(AppDbContext dbContext)
{
_users = dbContext.Users.AsNoTracking();
}
public Task<User[]> GetUsers()
=> _users.ToArrayAsync();
}Separate read and write contexts
Configure the read repository to use AsNoTracking by default, and then use the read-only DbContext when needed:
public class ReadOnlyAppDbContext : DbContext
{
public DbSet<User> Users { get; set; } = null!;
public ReadOnlyAppDbContext(DbContextOptions<ReadOnlyAppDbContext> options) :
base(options)
{
}
}
// When registering db context, add UseQueryTrackingBehavior
services.AddDbContext<ReadOnlyAppDbContext>(
opts => opts
.UseSqlServer(connectionString)
.UseQueryTrackingBehavior(QueryTrackingBehavior.NoTracking));Which one do I use?
Depends on the use case at hand. In case of web apps, I would start with Identity Resolution. As the app usage grows, I would look into having different models (projections) for read operations.
This has several advantages:
- The performance is improved by selecting only the data I really need. You can do this from the very beginning of development
- Projections are not tracked by default, as you can’t really update a projection
- For updates, I need to explicitly call
Updateon the repository/DbContext so it is clear that it will be updated
Notes on performance:
Reproducible example
The numbers shown in the table above looked a bit off. The performance improvement where something is 2-4x faster just by using AsNoTracking() does not quite add up. I don’t doubt the original author’s benchmark, but I was unable to produce similar results.
My testing produced slightly different results, with the difference being 8-16%. That is an order of magnitude less than 2-4x:
| Method | N | Mean | Ratio |
|--------------------- |------- |------------|-------|
| WithTracking | 1000 | 2.922 ms | 1.00 |
| WithoutTracking | 1000 | 3.167 ms | 1.08 |
| | | | |
| WithTracking | 10000 | 11.655 ms | 1.00 |
| WithoutTracking | 10000 | 12.694 ms | 1.09 |
| | | | |
| WithTracking | 100000 | 92.436 ms | 1.00 |
| WithoutTracking | 100000 | 106.700 ms | 1.16 |Try to push the processing of data to SQL Server
SQL Server is optimized for processing a lot of data in parallel. For example, calculating sum of numbers would execute much faster on SQL Server than it would if the data is loaded in memory first. This example is obvious, but many times I’ve encountered a process taking minutes to complete, while equivalent could be done by a single query in seconds.
For reporting, use data warehouses or read replicas
Try not to allow your reporting to impact the performance of your master database.
A lesson from the battlefield
Once I had to deal with a process that took very long time. When debugging, it would take some amount of time (let’s say 5s) per batch of 1000 entries. When same process is run on production environment, the batch processing time started increasing after each batch by a few milliseconds (let’s take 10 as example).
For one million users, this would take 55050 seconds in total, just a bit less than 15.3 hours.
The code was similar to this:
public async Task Process()
{
var batchNumber = 0;
var batchSize = 1000;
while (!IsDone)
{
var users = await _dbContext.Users
.Skip(batchSize * batchNumber)
.Take(batchSize)
.ToArrayAsync();
await ProcessUsers(users);
batchNumber++;
await _dbContext.SaveChangesAsync();
}
}Unfortunately, processing meant updating each row, so tracking had to be enabled.
The problem? Change tracker.
The first batch starts with an empty change tracker so it is very fast. Saving the changes goes only through the first 1k entities, so it is relatively fast.
The next one starts with 1000 tracked entities, and saving the changes now requires EF to go through 2k entities.
This quickly adds up.
The solution? Clear the change tracker.
In my case, we simply used a new DbContext for each batch. Of course, a bit more synchronizing had to be done in case the process failed in the middle of processing.
The code was similar to this:
public async Task Process()
{
var batchNumber = 0;
var batchSize = 1000;
while (!IsDone)
{
await using var scope = _serviceProvider.CreateAsyncScope();
var dbContext = scope.ServiceProvider.GetService<AppDbContext>();
var users = await dbContext.Users
.Skip(batchSize * batchNumber)
.Take(batchSize)
.ToArrayAsync();
ProcessUsers(users);
batchNumber++;
await dbContext.SaveChangesAsync();
}
}With change tracker issues eliminated, this process took around 5000 seconds, or 1.4 hours. An improvement of 11.01 times.