
In the previous part, a multi-threaded solution was created, that does not scale. Partitioning was used to split the data into smaller data sets each thread would process.
The next milestone is to create a scalable solution.
When talking about scalability, it is important to note that boundaries are always involved. A system is never designed to work for arbitrary workloads. Different workloads require different architectures (as we can see in this series). Maintaining architecture that is highly scalable when there is no business need for it is wasteful in terms of the developer’s time and computing power – both have consequences on the total dollar cost.
Your job, as a software developer is to implement a solution that serves the business in the foreseeable future and does not break the bank.
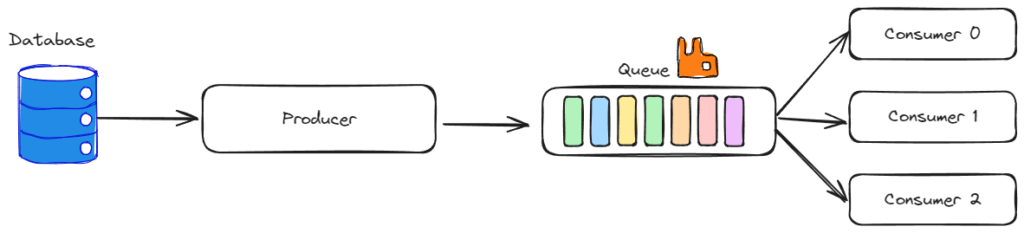
Producer-Consumer pattern
The previous solution managed to handle 28k notifications per minute on a single server. To get to the next level, we can look into:
- Enabling multiple consumers to process the data
- Optimize the processing to get more out of a single server
Using the Producer-Consumer pattern is a great way to achieve both.
The producer-Consumer pattern consists of three parts: Producer, Consumer, and a Queue.
The producer prepares the data for processing, by adding it to the queue. In this case, the producer loads the data from the database and puts it in the queue.
The queue is used as a buffer between the producer and consumers. Usually, a queue data structure is used for these purposes, but others can be used as well. In this specific case, RabbitMQ was used.
The consumer’s purpose is to process the data from the queue. There can be multiple consumers that consume data from the same queue. However, consumers will not process the same data.
For example, if Consumer 0 reads one item from the queue, that item will be locked while being processed. That means, if Consumer 1 tries to get an item for processing, it will return the next one. This is called Competing Consumers.
How is this pattern more scalable than using partitioning?
In the previous solution, we used partitioning so that the data each consumer processes is pre-defined. So if a new consumer is to be started, we have to change the configuration across all existing consumers.
In the case of Competing Consumers, when the load is increased, we simply have to start new consumers to meet the demand. This makes it easy to scale the services up to a certain point. And in case a consumer crashes, the data will still be processed, although a bit slower.
Producer
The repository on GitHub has a class Producer that reads 1000 notifications from the database, deletes them from the database, and puts them in the queue. And then repeats until one minute has passed.
Batch size
SQL Server works best when it can process data in parallel. That means, if we want to read 1000 entries from the database, reading them at once, rather than in a loop will yield much better results.
Of course, if we are working with large data sets, instead of reading all at once, it is a good idea to chunk the data.
In my tests, the producer managed to put around 850,000 messages in the queue in one minute. As this was not a bottleneck so far, I have not tried different values for batch size. Perhaps a batch size of 2000 is enough to produce more than 1 million messages?
Consumer
My consumer application has two distinct parts: MessageConsumer, and NotificationSender.
MessageConsumer
The purpose of MessageConsumer is to create a connection to RabbitMQ and create many NotificationSenders.
To get the best performance, the application needs to have a single connection to RabbitMQ and to create one channel per Consumer.
NotificationSender
The NotificationSender receives messages from the queue and handles them. After handling each message, the message needs to be confirmed, which will remove it from the queue.
To increase the performance of a notification sender, it is important to set the Quality of Service parameter:
channel.BasicQos(0, 100, false);This tells the channel to pre-fetch 100 messages per consumer. It helps reduce network hops and time loss when waiting for the next messages to be fetched.
Preliminary tests
In my local testing, the previous solution managed to get around 28k notifications per minute. This solution managed to get around 44k notifications per minute.
Why? After all, there is a new component (RabbitMQ) involved – we would expect a performance hit.
The answer lies in the producer. When reading the data in batches, it is much faster, so it offsets the performance losses added by using RabbitMQ. To further drive this point, here is a scenario you can test:
Try to insert 1 million records in the database by using a for loop. Then use the script provided in Scaling a notification service – Part 1 – Engineering With Filip. The provided script does this in seconds, while the loop will take hours.
Testing the solution
To test this solution, I needed multiple servers and a way to manage the services. I used Hetzner to rent cheap and powerful servers. For testing different configurations, I used docker swarm with docker-stack.yml file.
Measuring one minute in a distributed system
On a single system, it is easy to measure exactly one minute. It becomes a bit of a challenge in distributed systems. It might take a few seconds for the deployment of services to complete, and I wanted to make sure to test with all the services running.
The consumer has a KillSwitch implemented, which triggers shutdown one minute after the first message is received.
The producer waits one minute before sending any messages, to give time for consumers to start. Then it starts running for one minute and shuts itself down. The producer is not scaled at the moment, so there is no need for a sync mechanism between multiple producers and consumers.
Results
| No. of Producers | Messages produced | No. of Consumers | Messages consumer | No. of Servers | Consumer & Producer CPU usage | Database & Rabbit CPU % |
|---|---|---|---|---|---|---|
| 1 | 562000 | 64 | 161142 | 2 | 6/16 cores | 4/4 cores |
| 1 | 486000 | 128 | 173514 | 2 | 6/16 cores | 4/4 cores |
| 1 | 860000 | 64 | 198243 | 2 | 5/16 cores | 8/16 cores |
| 1 | 865000 | 128 | 273209 | 2 | 6/16 cores | 10/16 cores |
| 1 | 844000 | 192 | 305850 | 2 | 6/16 cores | 10/16 cores |
| 1 | 837000 | 2 apps x192 | 449274 | 2 | 9/16 cores | 12/16 cores |
Understanding the bottleneck
During the tests, the CPU was not fully utilized. Starting more instances of applications did not yield better results, and would not increase the CPU utilization.
This means there is a bottleneck in the algorithm or one of the components. It could be:
- SQL Server – the operations we do cause SQL server to be slow
- The settings for RabbitMQ QoS and batch size are not fine-tuned
- RabbitMQ can’t handle more messages in a single queue due to internal synchronization mechanisms
- The OS on the servers + .NET runtime does not work nicely with that many different threads and context-switching
Judging the solution
- Simplicity – I believe it is simple to understand, although it uses a new component, 4/5
- Scalability – 449k per minute. 1 million does not look so far away now – 3/5.
- Infrastructural complexity – We still allow only one producer. However, the consumer can be added to any existing service, making it simple to integrate – 4/5
Stay tuned for the next post: We will examine the potential bottlenecks and try to optimize them.
Bonus:
When messaging is used, there is either at-least-once delivery or at-most-once delivery.
In the case of our system, this refers to the notifications that we send. For each entry in the database, we can choose to deliver at least one email, or at most one email.
Why does this happen? The consumers in are idempotent and will not handle a notification if it is already handled, so it should not happen, right?
Failure scenario 1: At-least-once delivery
The NotificationSender has received a message. The message is deserialized, we check if this notification has already been handled, and see that the database does not contain a record.
So the next step is to send the email.
After sending the email, the system crashed, and the NotificationSender did not manage to save the log. The message will be back to the top of the queue and processed by another instance.
In this case, the second instance will send the email again. In case of fatal failures, we have no way of knowing if the message was processed or not, leading to duplicates. This is at-least-once delivery.
Failure scenario 2: At-most-once delivery
The NotificationSender has received a message. The message is deserialized, we check if this notification has already been handled, and see that the database does not contain a record.
To prevent sending the email twice, we remove the message from the queue just before sending it.
And then the system crashes and the email is not sent.
The message is removed and will not be picked up again. The system tried to deliver the message only once and it failed, hence the name at-most-once delivery.